音声¶
警告
警告! これはα版のコードです。
開発を続ける過程で、この API を変更する可能性があります。
音声の品質は大したものではなく、単に「十分に良い」レベルです。デバイスの制約により、再生中にメモリエラーや予期しない余分なサウンドが発生することがあります。まだ初期段階であり、音声シンセサイザーのコードを常に改善しています。バグレポートやプルリクエスは大歓迎です。
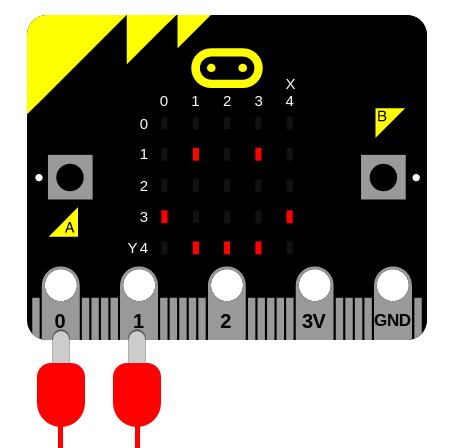
このモジュールで micro:bit に話をさせ、歌わせ、その他の音声のようなサウンドを作るのにスピーカーを以下に示すようにボードに接続するという前提で説明します。
注釈
この作業は、コモドール64のために1982年に最初にリリースされた SAM (Software Automated Mouth)と呼ばれる古い TTS (text-to-speech)プログラムに対して Sebastian Macke が行った驚くべきリバースエンジニアリングの努力に基づいています。結果として小さな C ライブラリが出きあがり、我々は micro:bit にそれを採用して適合させました。 彼のホームページ からもっと知ることができます 。このドキュメントの情報の多くは、ここ `here にある元のユーザーズマニュアルから取ってきています 。
音声シンセサイザーは、最大255文字のテキスト入力から約2.5秒分の音量を生成できます。
このモジュールにアクセスするには、以下を行う必要があります:
import speech
以降の例では、これが行われていることを前提としています。
関数¶
-
speech.translate(words)¶ 文字列
wordsにある英単語の並びについて、発声するのに最適な音素を推測して、文字列として返します。出力は、 このテキスト-音素変換テーブル にしたがって生成されます。この関数は、音素の近似を最初に生成するために使うべきです。この結果を元に手で編集して、精度、屈曲、強調を改善することができます。
-
speech.pronounce(phonemes, *, pitch=64, speed=72, mouth=128, throat=128)¶ 文字列
phonemesが表す音素を発声します。音声合成器の出力を細かく制御するために音素を使用する方法の詳細については後述します。オプションのピッチ、スピード、口、スロートの設定を上書きして、声の音色(音質)を変更します。
-
speech.say(words, *, pitch=64, speed=72, mouth=128, throat=128)¶ 文字列
wordsにある英単語の並びを発声します。結果は実際の英語の半分程度の精度です。オプションの pitch、speed、mouth、throat の設定を上書きして、声の音色(音質)を変更します。この関数は次の呼び出しを短くしたものです:speech.pronounce(speech.translate(words))
-
speech.sing(phonemes, *, pitch=64, speed=72, mouth=128, throat=128)¶ 文字列
phonemesが表す音素を歌います。音符のピッチと持続時間を変更する方法は後述します。オプションの pitch、speed、mouth、throat の設定を上書きして、声の音色(音質)を変更します。
句読点¶
句読点は、音声の伝達を変更するのに使います。シンセサイザーは、ハイフン、カンマ、フルストップ、疑問符の4つの句読点を認識します。
ハイフン (-)は音声に短い休止を入れることによって、句を区切ります。
カンマ (,)はハイフンの約2倍のポーズを挿入することにより、フレーズを区切ります。
終止符 (.) と疑問符 (?) の終了文。
終止符はポーズを挿入し、ピッチを落とします。
疑問符もポーズを挿入しますが、ピッチが上がります。これは 「are we home yet?」 のような yes/no で答えられる質問に適しています」why are we going home?」 のようなより複雑な質問では終止符を使ってください。
音色¶
音色は音の質です。それは、(たとえば) DALEK の声と人間の声の違いです。音色を制御するには、pitch, speed, mouth, throat 引数の数値設定を変更します。
pitch (音程の高低)と speed (音声の速さ)の設定はかなり明白で、一般的に次のカテゴリに分類されます。
pitch
- 0-20 実用的でない
- 20-30 非常に高い
- 30-40 高い
- 40-50 高めのノーマル
- 50-70 ノーマル
- 70-80 低めのノーマル
- 80-90 低い
- 90-255 非常に低い
(デフォルトは 64)
speed
- 0-20 実用的でない
- 20-40 非常に速い
- 40-60 速い
- 60-70 早口な会話
- 70-75 普通の会話
- 75-90 説話
- 90-100 遅い
- 100-225 非常に遅い
(デフォルトは 72)
mouth と throat の値は説明するのが少し難しく、以下の説明は、各設定の値が変更されたときに生成される音声の聴覚の印象に基づいています。
mouth の場合、数字が低いほど、スピーカーが唇を動かさずに話しているように聞こえます。対照的に、数字が高いほど(最大255)、声が誇張された口の動きで発声されるように聞こえます。
throat の数が少ないほど、スピーカーの響きが緩和されます。対照的に、数字が高いほど、緊張感が増します。
重要なことは、望む声の音を得る最良の方法は、実験を繰り返して調整することです。
とっかかりとして、いくつかの例を示しておきます:
speech.say("I am a little robot", speed=92, pitch=60, throat=190, mouth=190)
speech.say("I am an elf", speed=72, pitch=64, throat=110, mouth=160)
speech.say("I am a news presenter", speed=82, pitch=72, throat=110, mouth=105)
speech.say("I am an old lady", speed=82, pitch=32, throat=145, mouth=145)
speech.say("I am E.T.", speed=100, pitch=64, throat=150, mouth=200)
speech.say("I am a DALEK - EXTERMINATE", speed=120, pitch=100, throat=100, mouth=200)
音素¶
say 関数は音声を簡単に作成できます - しかし、正しくないことがよくあります。音声シンセサイザーにあなたの望むよう正しく発音させるためには、 音素を使う必要があります: 音素は知覚的に区別できる最小の単位で、異なる単語を区別するために使えます。基本的に、それは音声のビルディング・ブロック・サウンドです。
pronounce 関数は、簡略化された読みやすい形式の 国際音声アルファベット とオプションの注釈を含む文字列を使用して、屈曲と強調を示します。
音素を使用する利点は、綴り方を知る必要がないことです。むしろ、それを音声学的に綴るためには、言葉の使い方を知る必要があります。
以下の表は、シンセサイザが理解している音素の一覧です。
注釈
このテーブルには、音素と文字の例文が含まれています。例の単語は、音素の音を(かっこ内に)持ちますが、同じ文字である必要はありません。
見過ごされがちなこと: 「H」 の音のシンボルは /H です。声門停止は音の強制停止です
単純母音 有声音
IY f(ee)t R (r)ed
IH p(i)n L a(ll)ow
EH b(e)g W a(w)ay
AE S(a)m W (wh)ale
AA p(o)t Y (y)ou
AH b(u)dget M (S)am
AO t(al)k N ma(n)
OH c(o)ne NX so(ng)
UH b(oo)k B (b)ad
UX l(oo)t D (d)og
ER b(ir)d G a(g)ain
AX gall(o)n J (j)u(dg)e
IX dig(i)t Z (z)oo
ZH plea(s)ure
二重母音 V se(v)en
EY m(a)de DH (th)en
AY h(igh)
OY b(oy)
AW h(ow) 無声音
OW sl(ow) S (S)am
UW cr(ew) SH fi(sh)
F (f)ish
TH (th)in
特殊な音素 P (p)oke
UL sett(le) (=AXL) T (t)alk
UM astron(om)y (=AXM) K (c)ake
UN functi(on) (=AXN) CH spee(ch)
Q kitt-en (glottal stop) /H a(h)ead
次の非標準シンボルもユーザーが使用できます:
YX diphthong ending (weaker version of Y)
WX diphthong ending (weaker version of W)
RX R after a vowel (smooth version of R)
LX L after a vowel (smooth version of L)
/X H before a non-front vowel or consonant - as in (wh)o
DX T as in pi(t)y (weaker version of T)
あまり使われない音素の組み合わせ(および提案された選択肢)は次のとおりです:
PHONEME YOU PROBABLY WANT: UNLESS IT SPLITS SYLLABLES LIKE:
COMBINATION
GS GZ e.g. ba(gs) bu(gs)pray
BS BZ e.g. slo(bz) o(bsc)ene
DS DZ e.g. su(ds) Hu(ds)son
PZ PS e.g. sla(ps) -----
TZ TS e.g. cur(ts)y -----
KZ KS e.g. fi(x) -----
NG NXG e.g. singing i(ng)rate
NK NXK e.g. bank Su(nk)ist
上記の音素以外のものを使用すると ValueError 例外が発生します。音素を次のような文字列として渡します。
speech.pronounce("/HEHLOW") # "Hello"
音素は母音と子音という2つの大きなグループに分類されます。
母音はさらに単純母音と二重母音に分けられます。単純母音は発音してみるとおり音が変わることはありません。二重母音は一つの音で始まり別の音で終わります。たとえば 「oil」 という言葉を言うとき、」oi」 の母音は 「oh」 音で始まり、」ee」 音に変化します。
子音もまた有声音と無声音の2つのグループに分けられます。有声音は、その音声を生成するために、その有声子音のコードを使用する必要があります。たとえば、 「L」, 「N」, 「Z」 のような子音が発音されます。無声音の子音は、」P」, 「T」, 「SH」 などの急速な息によって生成されます。
一度このようなことに慣れると、音素システムは簡単です。まず、いくつかのスペルは難しいように見えるかもしれません(たとえば、 「adventure」 には 「CH」 があります)が、ルールはあなたが言うことを書くことであり、スペルは書きません。問題のある単語を解決するには、実験が最善の方法です。
音声は自然で分かりやすく理解できることも重要です。口頭による出力の質を向上させるために、内蔵のストレスシステムを使用して屈曲または強調を追加することはよくあります。
数字 1 - 8 で示される8つのストレスマーカーがあります。ストレスを与える母音の後に必要な番号を挿入するだけです。たとえば、」/HEHLOW」 の表記が欠けているのは、 「/HEH3LOW」 と書かれているとはるかに改善されています。
また、ストレスを感じる方法で言葉の意味を変えることも可能です。」Why should I walk to the store?」 というフレーズを考えてみてください。それはいくつかの異なる方法で発音することができます:
# You need a reason to do it.
speech.pronounce("WAY2 SHUH7D AY WAO5K TUX DHAH STOH5R.")
# You are reluctant to go.
speech.pronounce("WAY7 SHUH2D AY WAO7K TUX DHAH STOH5R.")
# You want someone else to do it.
speech.pronounce("WAY5 SHUH7D AY2 WAO7K TUX DHAH STOHR.")
# You'd rather drive.
speech.pronounce("WAY5 SHUHD AY7 WAO2K TUX7 DHAH STOHR.")
# You want to walk somewhere else.
speech.pronounce("WAY5 SHUHD AY WAO5K TUX DHAH STOH2OH7R.")
簡単に言えば、言葉遣いのストレスによって、表現力豊かな声調が得られます。
これらはあなたが与える数に応じて、ピッチを上げたり下げたり、関連する母音を伸ばしたりすることによって動作します:
- 非常に感情的なストレス
- 非常に強調したストレス
- かなり強いストレス
- 普通のストレス
- タイトストレス
- ニュートラル(ピッチ変化なし)ストレス
- ピッチ落ちストレス
- 極端なピッチ落ちのストレス
数値が小さいほど、極端に強調されます。しかし、このようなストレスマーカーは難しい言葉を正しく発音するのに役立ちます。たとえば、音節が十分に強調されていない場合は、中立のストレスマーカーを入れます。
ストレスマーカーを使って単語を伸ばすこともできます:
speech.pronounce("/HEH5EH4EH3EH2EH2EH3EH4EH5EHLP.”)
歌唱¶
MicroPython に音素を歌わせることは可能です。
これは音素にピッチ関連の番号を注釈することによって行います。数字が小さいほど、ピッチが高くなります。数字はおおよそ次の図に示すように音符に変換されます。

注釈は、音素の前にハッシュ記号(#)とピッチ番号をあらかじめ付けておくことにより有効となります。新しい注釈が与えられるまで、ピッチは同じままになります。たとえばを次のようにして MicroPython に音階を歌わせます。
solfa = [
"#115DOWWWWWW", # Doh
"#103REYYYYYY", # Re
"#94MIYYYYYY", # Mi
"#88FAOAOAOAOR", # Fa
"#78SOHWWWWW", # Soh
"#70LAOAOAOAOR", # La
"#62TIYYYYYY", # Ti
"#58DOWWWWWW", # Doh
]
song = ''.join(solfa)
speech.sing(song, speed=100)
特定の音符を歌わせるには、母音や母音の音韻を繰り返します(上記の例を参照)。二重母音に注意してください。これを伸ばすには、それらを構成部品に分解する必要があります。たとえば、 「OY」 は 「」OHOHIYIYIY」 で伸ばすことができます。
試聴、慎重な聴取、調整は、音を望むだけ伸ばすよう何回音素を繰り返すかを決める唯一確実な方法です。
どのような仕組みなのですか?¶
オリジナルのマニュアルはそれをうまく説明しています:
まず、実際の音声波形を記録する代わりに、周波数スペクトルのみを保存します。こうすることで、メモリを節約し、他の利点も得られます。第2に、私たちは […] タイミングに関するいくつかのデータを保存します。これらは、異なる状況下での各音素の継続時間に関連する数字があり、そしてまた遷移時間についてのいくつかのデータがあるので我々は隣り合った音素のブレンド方法を知ることができます。第3に私たちはこのデータをすべて処理するためのルールを考案しました。驚いたことにく、私たちのコンピュータはすぐに何かしゃべりはじめました。
—S.A.M. オーナマニュアル。
出力は audio モジュールによって提供される関数を介してパイプされます。あーら不思議、話す micro:bit のできあがりです。
サンプルコード¶
import speech
from microbit import sleep
# say メソッドは英語から音素への変換を試みます。
speech.say("I can sing!")
sleep(1000)
speech.say("Listen to me!")
sleep(1000)
# throat をクリーンにするには音素を使う必要があります。
# pitch と speed を変更することでも適切な効果が得られます。
speech.pronounce("AEAE/HAEMM", pitch=200, speed=100) # えへん
sleep(1000)
# 歌わせるには各音節ごとに音階の音素が必要です。
solfa = [
"#115DOWWWWWW", # ド
"#103REYYYYYY", # レ
"#94MIYYYYYY", # ミ
"#88FAOAOAOAOR", # ファ
"#78SOHWWWWW", # ソ
"#70LAOAOAOAOR", # ラ
"#62TIYYYYYY", # シ
"#58DOWWWWWW", # ド
]
# 音階が順に高くなっていくよう歌わせます。
song = ''.join(solfa)
speech.sing(song, speed=100)
# 音節のリストの順番を逆にします。
solfa.reverse()
song = ''.join(solfa)
# 音階が順に低くなっていくよう歌わせます。
speech.sing(song, speed=100)