| < 1> < 2> < 3> < 4> | if(((c>=0x81)&&(c<=0x9f))||((c>=0xe0)&&(c<=0xfc)))return 1; else return 0; } |
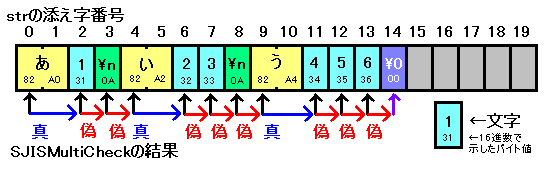
| < 1> < 2> < 3> < 4> < 5> < 6> < 7> < 8> < 9> < 10> < 11> < 12> < 13> < 14> < 15> < 16> < 17> < 18> < 19> < 20> < 21> < 22> < 23> < 24> < 25> < 26> < 27> < 28> < 29> < 30> < 31> < 32> < 33> < 34> | int SJISMultiCheck(unsigned char c){ if(((c>=0x81)&&(c<=0x9f))||((c>=0xe0)&&(c<=0xfc)))return 1; else return 0; } int StringCount(const char *str){ /***************************** strの文字列の文字数を返す関数(日本語対応) 戻り値:strの文字数 const char *str:文字数を数える文字列 *****************************/ int i,cnt=0; for(i=0;str[i]!='\0';){//(1) if(SJISMultiCheck(str[i]))i+=2; else i++; cnt++; } return cnt; } int main(void){ char str1[11]="abcde"; char str2[11]="あいうえお"; char str3[21]="あ1\nい23\nう456"; printf("%sの長さ:%d\n\n",str1,StringCount(str1)); printf("%sの長さ:%d\n\n",str2,StringCount(str2)); printf("%sの長さ:%d\n\n",str3,StringCount(str3)); //終了待ち getchar(); return 0; } |