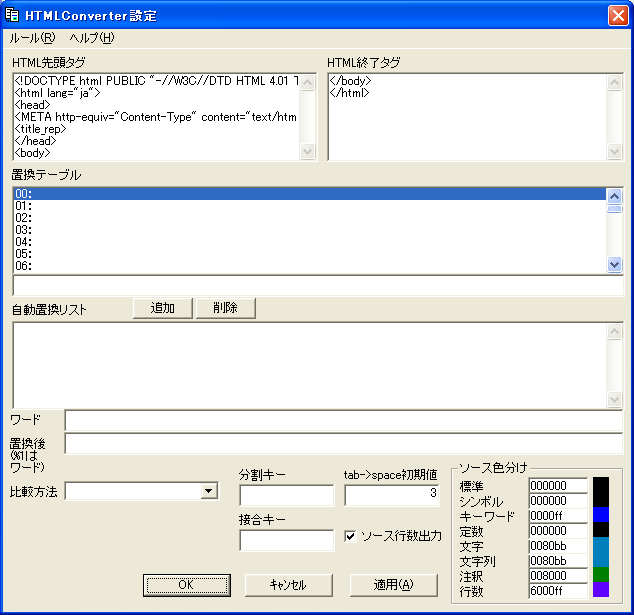
| 抲姺僞僌 | 岠壥 |
|---|---|
| <title_rep> | 抲姺柦椷乽title乿偱嵟屻偵愝掕偝傟偨title僞僌偵抲姺偝傟傑偡丅 |
| <exrepX> | 抲姺柦椷乽exrepsX,exrepeX乿偱嵟弶偵愝掕偝傟偨暥帤楍偵抲姺偝傟傑偡丅 |
| <nowdate_rep> | 曄姺偟偨擔晅偵抲姺偝傟傑偡丅 |
| <nowtime_rep> | 曄姺偟偨帪崗偵抲姺偝傟傑偡丅 |
| <filedate_rep> | 栚昗傪峏怴偟偨擔晅偵抲姺偝傟傑偡丅 |
| <filetime_rep> | 栚昗傪峏怴偟偨帪崗偵抲姺偝傟傑偡丅 |
| 柦椷 | 岠壥 |
|---|---|
| table= | 僥乕僽儖儌乕僪偺奐巒丅奼挘忣曬偼table僞僌偺堷悢偵丄峴僨乕僞偼僞僽嬫愗傝偱尒弌偟偵巊梡偟傑偡丅 |
| endtable | 僥乕僽儖儌乕僪偺廔椆丅 |
| cppsrc | C/C++僜乕僗怓曄偊儌乕僪偺奐巒丅懡廳偱偒傑偣傫丅 |
| endcppsrc | C/C++僜乕僗怓曄偊儌乕僪偺廔椆丅 |
| base | 帺摦揑偵巜掕偝傟傞柦椷暥帤楍(扨撈丄峴柦椷巜掕)傪愝掕偟傑偡丅愝掕抣偼峴僨乕僞丅 偙偙偱巜掕偟偨柦椷暥帤楍偼奺峴偺愭摢偵彂偄偨偺偲摨媊偱偡丅 夝彍偡傞偵偼嬻暥帤楍傪嵞愝掕偟偰偔偩偝偄丅 |
| ini | hci僼僅儖僟偵偁傞愝掕僼傽僀儖傪撉傒崬傒傑偡丅 僼傽僀儖柤偼峴僨乕僞丅 僼傽僀儖柤偺奼挘巕偼昁梫偁傝傑偣傫丅 愝掕僼傽僀儖偵婰弎偝傟偰偄傞撪梕傪偙傟埲崀偺曄姺梡偵撉傒崬傒傑偡丅 HTML愭摢僞僌側偳偼嵟屻偵撉傒崬傫偩愝掕僼傽僀儖偺傕偺偑巊傢傟傑偡丅 |
| title | 僿僢僟乕偺<title_rep>偵儁乕僕僞僀僩儖偲偟偰抲姺偝傟傞柤慜傪愝掕偟傑偡丅柤慜偼峴僨乕僞丅 |
| exrepsX | 僿僢僟乕偺<exrepX>傪抲姺偟傑偡丅抲姺暥帤楍偼峴僨乕僞丅 |
| exrepeX | 廔椆僞僌偺<exrepX>傪抲姺偟傑偡丅抲姺暥帤楍偼峴僨乕僞丅 |
| setsplit | 暘妱僉乕傪嵞愝掕偟傑偡丅怴偟偄暘妱僉乕偼峴僨乕僞丅 |
| setjoin | 愙崌僉乕傪嵞愝掕偟傑偡丅怴偟偄愙崌僉乕偼峴僨乕僞丅 |
| /* | 僗僉僢僾偺奐巒丅*/柦椷偑弌尰偡傞傑偱懠偺柦椷傗暥帤楍偼柍帇偝傟傑偡丅 |
| */ | 僗僉僢僾偺廔椆丅 |
| 柦椷 | 岠壥 |
|---|---|
| tabcnt= | 僞僽暥帤傪僗儁乕僗偵曄姺偡傞帪偺暥帤悢傪愝掕偟傑偡丅奼挘忣曬偼敿妏悢帤偱僗儁乕僗悢丅 |
| hr | <hr>(宺慄)偵側傝傑偡丅 |
| hr= | <hr>(宺慄)偺堷悢傪奼挘忣曬偵捈愙巜掕偟傑偡丅 |
| img= | <img>(夋憸)偵側傝傑偡丅奼挘忣曬偼src梫慺偵巜掕偡傞夋憸URL偱偡丅 |
| alt= | <img>(夋憸)偵側傝傑偡丅奼挘忣曬偼alt梫慺偵巜掕偡傞夋憸夝愢偱偡丅img=柦椷偑側偄応崌偼柍帇偟傑偡丅 |
| br | <br>(夵峴)偵側傝傑偡丅 |
| - | 愭峴攝抲扨敪僞僌丅=偼偮偄偰偄傑偣傫偑丄奼挘忣曬偼攝抲偟偨偄僞僌偱偡丅<>偼帺摦晅梌偟傑偡丅 |
| + | 捠忢攝抲扨敪僞僌丅=偼偮偄偰偄傑偣傫偑丄奼挘忣曬偼攝抲偟偨偄僞僌偱偡丅<>偼帺摦晅梌偟傑偡丅 |
| / | -傑偨偼+柦椷偱攝抲偟偨扨敪僞僌偺廔椆丅=偼偮偄偰偄傑偣傫偑丄奼挘忣曬偼廔椆偟偨偄僞僌偱偡丅</ >偼帺摦晅梌偟傑偡丅 |
| repX | 抲姺僥乕僽儖偺巜掕斣崋偺暥帤楍傪攝抲偟傑偡丅 傑偨丄幚峴帪帺摦愝掕偝傟傞抲姺僥乕僽儖偲偟偰埲壓偺斣崋傕巜掕偱偒傑偡丅 100=僼傽僀儖偺峏怴擭寧擔 101=僼傽僀儖偺峏怴帪崗 102=幚峴帪偺擭寧擔 103=幚峴帪偺帪崗 104=曄姺僼傽僀儖柤 |
| setrepX= | 抲姺僥乕僽儖偺巜掕斣崋偺暥帤楍傪愝掕偟傑偡丅奼挘忣曬偼愝掕偡傞暥帤楍偱偡丅 |
| include= | 巜掕僼傽僀儖傪揥奐偟傑偡丅奼挘忣曬偼曄姺拞僼傽僀儖偐傜偺憡懳僷僗僼傽僀儖柤偱偡丅 |
| indent= | 巜掕悢偺僗儁乕僗傪攝抲偟傑偡丅奼挘忣曬偼敿妏悢帤偱僗儁乕僗悢丅1-128偺斖埻丅 |
| next | 尰嵼偺峴偲師偺峴傪寢崌偟傑偡丅 |
| prev | 慜偺峴偲尰嵼偺峴傪寢崌偟傑偡丅 |
| ins | next偲prev偺椉巜掕丅 |
| conv | HTML曄姺儌乕僪傪ON偵偟傑偡丅 |
| noconv | HTML曄姺儌乕僪傪OFF偵偟傑偡丅 |
| autobr | 帺摦夵峴儌乕僪(夵峴帪偵<br>僞僌傑偨偼<tr>僞僌傪杽傔崬傓)傪ON偵偟傑偡丅 |
| noautobr | 帺摦夵峴儌乕僪(夵峴帪偵<br>僞僌傑偨偼<tr>僞僌傪杽傔崬傓)傪OFF偵偟傑偡丅 |
| start | HTML曄姺儌乕僪偲帺摦夵峴儌乕僪傪ON偵偟傑偡丅 |
| stop | HTML曄姺儌乕僪傪OFF丄帺摦夵峴儌乕僪傪ON偵偟傑偡丅 |
| nobrstart | HTML曄姺儌乕僪傪ON丄帺摦夵峴儌乕僪傪OFF偵偟傑偡丅 |
| nobrstop | HTML曄姺儌乕僪偲帺摦夵峴儌乕僪傪OFF偵偟傑偡丅 |
| srclineout | C/C++僜乕僗怓曄偊儌乕僪偱峴斣崋弌椡傪ON偵偟傑偡丅 |
| nosrclineout | C/C++僜乕僗怓曄偊儌乕僪偱峴斣崋弌椡傪OFF偵偟傑偡丅 |
| 儌乕僪柤 | ON帪岠壥 | ON偵偡傞柦椷 | OFF偵偡傞柦椷 |
|---|---|---|---|
| HTML曄姺 | 梫慺暥帤楍傪HTML偱偦偺傑傑昞帵偱偒傞傛偆偵僄僗働乕僾偟傑偡丅 | conv,start,nobrstart | noconv,stop,nobrstop |
| 帺摦夵峴 | 夵峴帪偵<br>僞僌傑偨偼<tr>(僥乕僽儖儌乕僪帪)僞僌傪晅梌偟傑偡丅 | autobr,start,stop | noautobr,nobrstart,nobrstop |
| 僥乕僽儖 | 暘妱僉乕傪僞僽暥帤(\t)丄愙崌僉乕傪<td>僞僌偵堦帪揑偵愝掕偟傑偡丅 帺摦夵峴儌乕僪帪偵傕<tr>僞僌傪晅梌偡傞傛偆偵側傝傑偡丅 暋悢夞ON偵偡傞偲椵愊偝傟丄僥乕僽儖偺拞偵僥乕僽儖偑嶌傟傑偡丅 椵愊傪慡偰夝彍偟偰OFF偵側傞偲暘妱僉乕偲愙崌僉乕偼暅尦偝傟傑偡丅 | table= | endtable |
| C/C++僜乕僗怓曄偊 | ON偵側偭偨嬫娫傪C/C++僜乕僗偲偟偰怓曄偊傪峴偄傑偡丅 ON偵側偭偰偄傞娫丄endcppsrc柦椷埲奜偺柦椷傪柍帇偟傑偡丅 攝怓偼愝掕僼傽僀儖偱愝掕偟偰偔偩偝偄丅 | cppsrc | endcppsrc |
| 柦椷 | 岠壥 |
|---|---|
| // | 奩摉梫慺傪柍帇偟傑偡丅 |
| b | <b>(懢帤)偵側傝傑偡丅 |
| i | <i>(幬懱)偵側傝傑偡丅 |
| tt | <tt>(摍暆)偵側傝傑偡丅 |
| pre | <pre>(惍宍嵪傒)偵側傝傑偡丅 |
| big | <big>(戝帤)偵側傝傑偡丅 |
| bigX | X屄偺<big>(戝帤)偵側傝傑偡丅 |
| small | <small>(彫帤)偵側傝傑偡丅 |
| smallX | X屄偺<small>(彫帤)偵側傝傑偡丅 |
| center | <center>(拞墰懙偊)偵側傝傑偡丅 |
| hX | <h1乣h6>僞僌偵側傝傑偡丅X偼斣崋丅偙偺柦椷偼next傪埫栙偵巜掕偟傑偡丅 |
| font= | <font>(彂懱巜掕)偺堷悢傪奼挘忣曬偵捈愙巜掕偟傑偡丅 |
| color= | <font>(彂懱巜掕)偵側傝傑偡丅奼挘忣曬偼color梫慺偵巜掕偡傞怓巜掕(怓柤 or 僇儔乕僐乕僪)偱偡丅 奼挘忣曬偺1暥帤栚偑 " 偱柍偄応崌偼丄帺摦揑偵""偱奼挘忣曬傪埻傒傑偡丅 |
| size= | <font>(彂懱巜掕)偵側傝傑偡丅奼挘忣曬偼size梫慺偵巜掕偡傞暥帤僒僀僘偱偡丅 奼挘忣曬偺1暥帤栚偑 " 偱柍偄応崌偼丄帺摦揑偵""偱奼挘忣曬傪埻傒傑偡丅 |
| a= | <a>(儕儞僋)偺堷悢傪奼挘忣曬偵捈愙巜掕偟傑偡丅 |
| link= | <a>(儕儞僋)偵側傝傑偡丅奼挘忣曬偼href梫慺偵巜掕偡傞儕儞僋愭URL偱偡丅 奼挘忣曬偺1暥帤栚偑 " 偱柍偄応崌偼丄帺摦揑偵""偱奼挘忣曬傪埻傒傑偡丅 |
| target= | <a>(儕儞僋)偵側傝傑偡丅奼挘忣曬偼target梫慺偵巜掕偡傞僼儗乕儉柤偱偡丅 奼挘忣曬偺1暥帤栚偑 " 偱柍偄応崌偼丄帺摦揑偵""偱奼挘忣曬傪埻傒傑偡丅 |
| name= | <a>(儕儞僋)偵側傝傑偡丅奼挘忣曬偼name梫慺偵巜掕偡傞柤慜偱偡丅 奼挘忣曬偺1暥帤栚偑 " 偱柍偄応崌偼丄帺摦揑偵""偱奼挘忣曬傪埻傒傑偡丅 |
| span= | <span>偺堷悢傪奼挘忣曬偵捈愙巜掕偟傑偡丅 |
| plain | 奩摉梫慺偼HTML曄姺傪嫮惂柍岠丅 |
| lconv | 奩摉梫慺偼HTML曄姺傪嫮惂桳岠丅 |
| 柦椷 | 岠壥 | 暘椶 |
|---|---|---|
| cppsrc | C/C++僜乕僗怓曄偊儌乕僪偺奐巒丅懡廳偱偒傑偣傫丅 | 攔懠柦椷 |
| endcppsrc | C/C++僜乕僗怓曄偊儌乕僪偺廔椆丅 | 攔懠柦椷 |
| base | 帺摦揑偵巜掕偝傟傞柦椷暥帤楍(扨撈丄峴柦椷巜掕)傪愝掕偟傑偡丅愝掕抣偼峴僨乕僞丅 偙偙偱巜掕偟偨柦椷暥帤楍偼奺峴偺愭摢偵彂偄偨偺偲摨媊偱偡丅 夝彍偡傞偵偼嬻暥帤楍傪嵞愝掕偟偰偔偩偝偄丅 | 攔懠柦椷 |
| setsplit | 暘妱僉乕傪嵞愝掕偟傑偡丅怴偟偄暘妱僉乕偼峴僨乕僞丅 | 攔懠柦椷 |
| setjoin | 愙崌僉乕傪嵞愝掕偟傑偡丅怴偟偄愙崌僉乕偼峴僨乕僞丅 | 攔懠柦椷 |
| /* | 僗僉僢僾偺奐巒丅*/柦椷偑弌尰偡傞傑偱懠偺柦椷傗暥帤楍偼柍帇偝傟傑偡丅 | 攔懠柦椷 |
| */ | 僗僉僢僾偺廔椆丅 | 攔懠柦椷 |
| br | <br>(夵峴)偵側傝傑偡丅 | 扨撈柦椷 |
| srclineout | C/C++僜乕僗怓曄偊儌乕僪偱峴斣崋弌椡傪ON偵偟傑偡丅 | 扨撈柦椷 |
| nosrclineout | C/C++僜乕僗怓曄偊儌乕僪偱峴斣崋弌椡傪OFF偵偟傑偡丅 | 扨撈柦椷 |
| center | <center>(拞墰懙偊)偵側傝傑偡丅 | 宲懕柦椷 |
| hX | <h1乣h6>僞僌偵側傝傑偡丅X偼斣崋丅偙偺柦椷偼next傪埫栙偵巜掕偟傑偡丅(1.02埲忋) | 宲懕柦椷 |